

 Goo Truther
Goo Truther  @thufie@pixie.town
@thufie@pixie.town
- site (with contact info)
- https://thufie.lain.haus
- pronouns
-
 or fae/faer/faerself
or fae/faer/faerself
- PeerTube
- @thufiefilms@bark.video
Admin
Þufie ![]() BLM
BLM ![]() ~
~ ![]()
![]() ~
~ ![]()
languages: en:✔️ he:~ es:~ ru:~
Reluctant moderator on social.pixie.town
Most online member of the system
#yesbot #nobot #noarchive I'm in my 20s, as a Computer Science researcher (Not in "AI" 🙄). Also a YouTuber now apparently, making YouTube Poops.
.אין דין ואין דיין. שלום בעולם
Programmer and IT girl. Pseudo-vegan for the environment (-avocados +oysters). Very uncomfortable with astrology. Please don't call me "dude", "bro", "man", etc. Radical egalitarian anarchist, hierarchies and hate are incompatible with a free and equal life ![]() .
. ![]() If you hate stoners just dni. I am also a trans woman so I *checks notes* meme about femininity and feminization sometimes. After dark account at: @thufieplus but read my bio there before sending a follow request even if we are already mutuals here. Oh and just to be clear because I think I see other white people on here trying to fake not being white under a bunch of other text, I'm just a disoriented white girl trying her best.
If you hate stoners just dni. I am also a trans woman so I *checks notes* meme about femininity and feminization sometimes. After dark account at: @thufieplus but read my bio there before sending a follow request even if we are already mutuals here. Oh and just to be clear because I think I see other white people on here trying to fake not being white under a bunch of other text, I'm just a disoriented white girl trying her best.
![]()
![]()
![]()
![]() Relationship Anarchist
Relationship Anarchist![]()
A list of licenses which respect OUR freedom (not just for software you dorks):
https://write.pixie.town/licenses-for-freedom/list-of-licenses-for-freedom
programming languages? ![]()
![]() C++ C MIPS x86 Java and a few others :P
C++ C MIPS x86 Java and a few others :P
Joined May 2019

As I do each morning, I was looking over my notes from yesterday and, no kidding, there is one that reads "I somehow didn’t finish my" — and that's it. I have no idea what it was going to say in full, not even with the context of the other notes around the half-sentence.

POLYCULE DATE SCHEDULING FOUND TO BE NP-HARD

Friends, for something to be open source, we need to see
1. The data it was trained and evaluated on
2. The code
3. The model architecture
4. The model weights.
DeepSeek only gives 3, 4. And I'll see the day that anyone gives us #1 without being forced to do so, because all of them are stealing data.
OH
You know shadow clone jutsu isn't real right?
You know polyamory isn't real right?
You know ninjas aren't real right?
C/C++ musing
I wonder if spawning multiple threads to read files at partitioned offsets and doing merging work to put it back together makes sense when parsing sufficiently large text files... Maybe with pread() I could make something fast, partititioning at units of filesystem block size to avoid cache misses... However I am not sure all the code involved would have thread-safe varieties.

popping cabbage

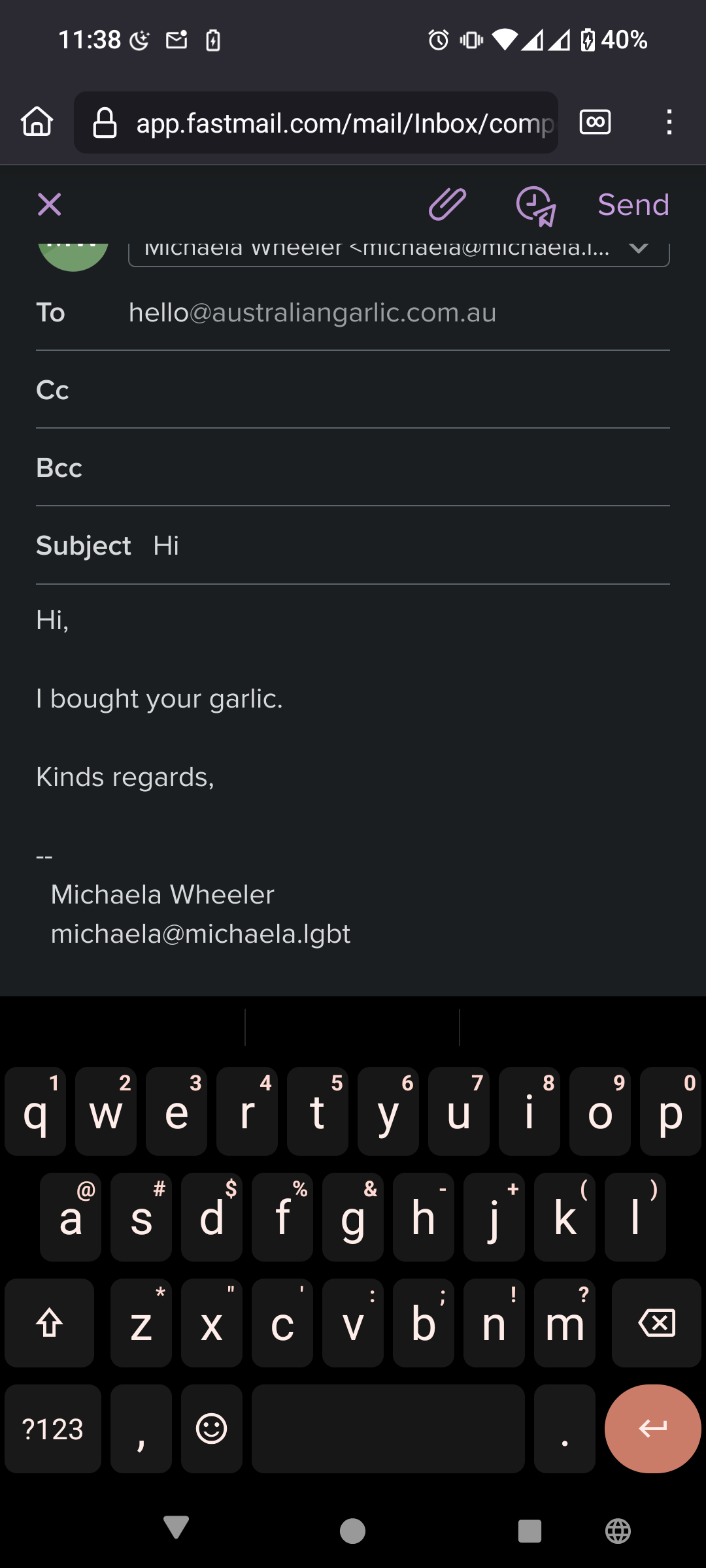
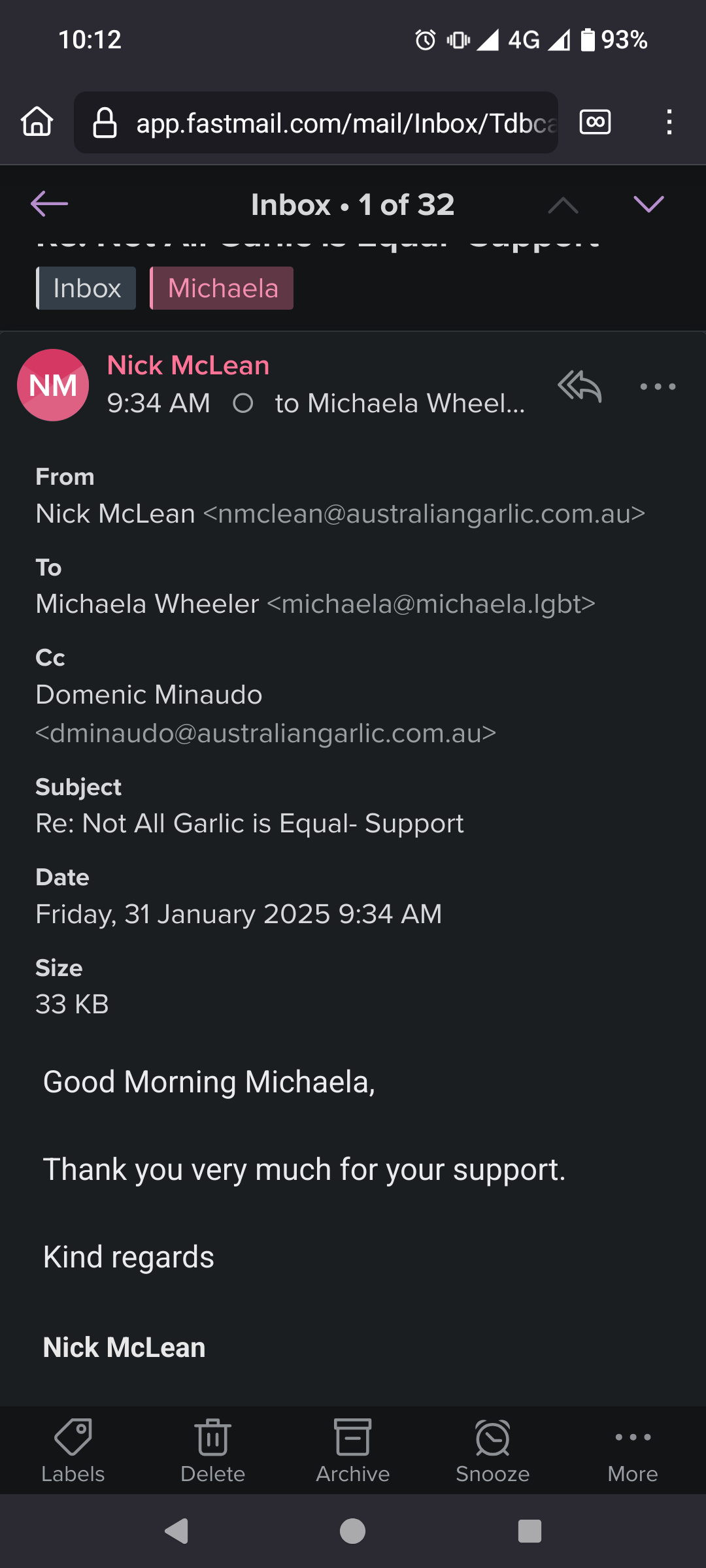
I emailed the email address on the garlic we purchased. That's all.
I have mastered posts that serve as their own apology. I am immortal.
wife-augmented posting
silly, self-deprecating, typos
sory for posting that besties... its was my evil yakubian programming. I will try to be beter!!!!.! 😭

do american furries use paws to measure stuff
KCachegrind is actually a really nice profiling dump visualizer. Shame it probably won't tell me anything I don't already know.

mare in the mountain myth
Jest: "squash commit"? what, does the 'g' in git stand for "gourd"?
Watch out folks.
It is an ![]() scrapes
scrapes ![]() world out there
world out there

"There’s substantial evidence that what DeepSeek did here is they distilled the knowledge out of OpenAI’s models and I don’t think OpenAI is very happy about this."
"I will explain what this means in a moment, but first: Hahahahahahahahahahahahahahahaha hahahhahahahahahahahahahahaha.
https://www.404media.co/email/855bf870-82ce-4544-8776-2225627fa39d/
- site (with contact info)
- https://thufie.lain.haus
- pronouns
-
or fae/faer/faerself
- PeerTube
- @thufiefilms@bark.video
Admin
Þufie ![]() BLM
BLM ![]() ~
~ ![]()
![]() ~
~ ![]()
languages: en:✔️ he:~ es:~ ru:~
Reluctant moderator on social.pixie.town
Most online member of the system
#yesbot #nobot #noarchive I'm in my 20s, as a Computer Science researcher (Not in "AI" 🙄). Also a YouTuber now apparently, making YouTube Poops.
.אין דין ואין דיין. שלום בעולם
Programmer and IT girl. Pseudo-vegan for the environment (-avocados +oysters). Very uncomfortable with astrology. Please don't call me "dude", "bro", "man", etc. Radical egalitarian anarchist, hierarchies and hate are incompatible with a free and equal life ![]() .
. ![]() If you hate stoners just dni. I am also a trans woman so I *checks notes* meme about femininity and feminization sometimes. After dark account at: @thufieplus but read my bio there before sending a follow request even if we are already mutuals here. Oh and just to be clear because I think I see other white people on here trying to fake not being white under a bunch of other text, I'm just a disoriented white girl trying her best.
If you hate stoners just dni. I am also a trans woman so I *checks notes* meme about femininity and feminization sometimes. After dark account at: @thufieplus but read my bio there before sending a follow request even if we are already mutuals here. Oh and just to be clear because I think I see other white people on here trying to fake not being white under a bunch of other text, I'm just a disoriented white girl trying her best.
![]()
![]()
![]()
![]() Relationship Anarchist
Relationship Anarchist![]()
A list of licenses which respect OUR freedom (not just for software you dorks):
https://write.pixie.town/licenses-for-freedom/list-of-licenses-for-freedom
programming languages? ![]()
![]() C++ C MIPS x86 Java and a few others :P
C++ C MIPS x86 Java and a few others :P
Joined May 2019
Goo Truther 's choices:



{kind=link}
{kind=link}
{kind=link}
