

Forest @forestjohnson@pixie.town
- member of
- https://cyberia.club
- webmaster @
- https://capsul.org/
I am a web technologist who is interested in supporting and building enjoyable ways for individuals, organizations, and communities to set up and maintain their own server infrastructure, including the hardware part.
I am currently working full time as an SRE 😫, but I am also heavily involved with Cyberia Computer Club and Layer Zero
Joined Feb 2021
Also, it goes without saying, but its ridiculous that if I want this capability, the only way to get it is to bootleg it like this.
Google finally achieved a technology that can transcribe spoken conversation, but they want to hoard it behind proprietary APIs and services. This bootleg is a small glimpse at what technology could be like if its goal was to provide utility instead of just make money: Accessibility technology that actually works!
Ok, ok, maybe that's a bit of a grandiose claim for something like this which is just barely demo-able and still has tons of difficult fundamental problems to overcome... But the point is, this capability would probably be commonplace already if it was open technology. The only reason this is remarkable is because I went through the effort to hack it together with DACs on both sides, special audio cables, android UI testing libraries, and heaps of good old-fashioned software duct-tape. And despite all that, it still out-performs the "Open" state of the art like "OpenAI" Whisper, while using 1/10th of the energy.
Also, here is the massive alt-text I wrote for the video :P A thorough description of wtf is going on in this video:
video of multi-user audio transcription system based on Pixel 6 phone with a neural network chip that enables the Google Live Transcribe app to convert audio into text without the ability to reach the internet.
The Pixel 6 is connected to a combo charger + microphone adapter. The Linux server has a sound card with its output connected to the microphone adapter's input, mediated by a special attenuator audio cable.
The linux server is running a web application that connects to a mumble server, enqueues audio from a conversation, and plays it back one-speaker-at-a-time.
The linux server is also attached to the android phone via ADB. The linux server join's the android phone's WiFi Hotspot. The linux server is running a "uiautomator" UI test which constantly polls the transcribed text element of the Google Live Transcribe app and posts the text to the server via WiFi.
The web application synthesizes the data of who was talking when, and what text was displayed when, in order to display the live conversation on a web-page, similar to a chat log.
These are the repos involved:
https://git.sequentialread.com/forest/mixtape-mumble
https://git.sequentialread.com/forest/mixtape/src/branch/main/mixtape.uiautomator
Here's a link to the video on my server: https://picopublish.sequentialread.com/files/mixtape-demo5.mp4
its kinda hard to hear @fack, I had my phone sitting on my headphones while recording this and it didn't work out too well
About 5 watts at the wall. A purely self-hosted live transcription of a Mumble audio chat. Transcription annotated by the speaker's name.
(resilvering)
Forest
boosted

@abucci i think its been like this since before GPTs. Its nothing new. History has shown that human samplers do a much better job of stealing others work and atapting it than GPTs have achieved so far. I'm not that concerned. I think this is just how the game of technology is played ...
The benefit has always been that you are always free to sample from the work of others that came before you. We don't have to figure everything out for ourselves every time we're born and brought up -- we are fed by industry that came before us. And likewise with ideas and theories.
> What are compelling visions of the future of automation that _aren't_ burying the exploitation behind an app or within a billion-parameter model?
This is a really weird question, because you wrote:
> future of automation that _aren't_ burying the exploitation
That's a bizzare sentence structure, its almost like its using rhetoric to try to exclude the possibility that there is no exploitation.
So, I would say, that's the answer to your question. The compelling vision of the future is that.... It's not a GIVEN that there must be exploitation. That automation can be re-imagined with an "anarchist" or "humanist" value-building framework that in itself, excludes exploitation.
That was the original dream of the open-source movement pre-co-optation by the elite, i.e. the Linux Foundation.
I believe this dream is still alive in permacomputing communities, community-oriented social media hosting orgs, etc. And honestly it doesn't have much to do with LLMs. We don't really have to care about LLMs or neural network GPU farms. If they are as hamstrung and "useless" as their detractors claim, they really aren't much to be concerned with.
Forest
boosted

An insightful comment by the chair of the National Transportation Safety Board.
Forest
boosted

{kind=link}
{kind=link}
{kind=link}
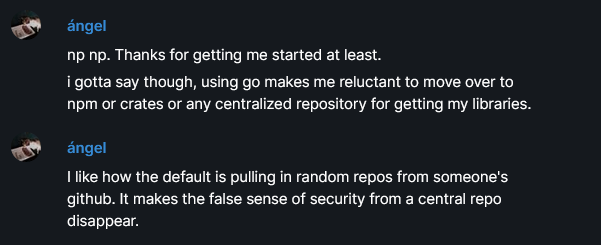
@filippo You are right that considering how much effort went into making this system hard to abuse, it's kinda insane that people like me will still complain about it, sr.ht will block it, and fedora will disable it by default.
I think a lot of that is simply because of
> "if it looks like a duck, if it quacks like a duck...."
No one has enough time in their day to actually research and understand this super-complicated system, they simply find out one day that `go get` is not connecting to the server that they thought it was connecting to, and they treat it just like anything else which has unexpected "seemingly secret" behaviour:
They have a knee-jerk reaction and block it.
IMO this whole misunderstanding could be avoided if the `go get` command would print a log message about its behaviour that includes a URL to an ELI5 version of the https://go.dev/ref/mod#checksum-database doc section.
I would be willing to write that doc if there was a chance it would be published that way.
This is a really good doc that explains how it works,
https://go.dev/ref/mod#checksum-database
> The checksum database is served by sum.golang.org, which is run by Google.
TBH I didn't know how it worked until I read this page just now, its really clever how it's designed, it sounds like the `go get` command really does try to avoid just blindly trusting whatever the proxy says, and while it does trust whatever the sumdb says, since the sumdb is a merkle tree and all responses are signed by the server's key, its highly tamper-proof.
> the first step is to retrieve the record data through the /lookup endpoint. If the module version is not yet recorded in the log, the checksum database will try to fetch it from the origin server before replying. This /lookup data provides the sum for this module version as well as its position in the log, which informs the client of which tiles should be fetched to perform proofs. The go command performs “inclusion” proofs (that a specific record exists in the log) and “consistency” proofs (that the tree hasn’t been tampered with) before adding new go.sum lines to the main module’s go.sum file.
> hearing from 90+% of go developers
Sorry, this was worded poorly, what I meant was, everyone I meet who uses go tends to fall into one of three camps:
25%: Knows about go proxy and go sumdb because they read about it on a social media posts like this one
70%: Thinks that `go get` directly connects to the server domain listed in `go.mod`
5%: Knows about go proxy and go sumdb because it broke their build
I have yet to meet anyone who learned about it by reading the documentation.
@filippo Like, even if it just printed a log by default
> Now I am connecting to the default go package proxy `proxy.golang.org`
> Now I am checking this hash `1a2b3c4d5e6f......` against the go sum db at `sum.golang.org`
That would address what I'm complaining about.
Even better, it would overwrite the lines in your `go.mod` , i.e.,
from
```
require (
git.sequentialread.com/forest/config-lite 164dc71bce04989dc5ffbbfd5769a689230f126a
)
```
to
```
require (
proxy.golang.org/git.sequentialread.com/forest/config-lite 164dc71bce04989dc5ffbbfd5769a689230f126a
)
```
> when there’s plenty of docs about the whole thing
Aka "RTFM", doesn't sound great here.
I _**know**_ it's misleading directly from my lived experience, and from hearing from 90+% of go developers who had exactly the same incorrect mental model of `go get`.
Whether it talks about this in some manual page somewhere or not doesn't really matter; no one is going to read that until after they discover that `go get` isn't doing what they expected.
The affordances and apparent behavior of the tool are the only way to "explain" this to users so they know what they're getting.
@filippo I use the word "misleading" because pretty much every golang developer I run into (including myself before this issue thread) has no idea that this feature exists, and their mental model of what go get is doing is wrong.
{kind=link}
- member of
- https://cyberia.club
- webmaster @
- https://capsul.org/
I am a web technologist who is interested in supporting and building enjoyable ways for individuals, organizations, and communities to set up and maintain their own server infrastructure, including the hardware part.
I am currently working full time as an SRE 😫, but I am also heavily involved with Cyberia Computer Club and Layer Zero
Joined Feb 2021
