

Sven Slootweg @joepie91@pixie.town
- Website
- http://cryto.net/~joepie91/
- Matrix
- @joepie91:pixie.town
- Pronouns
- they/them, he/him, whatever, it's not like I have any idea either 🙃
Technical debt collector and general hype-hater. Early 30s, non-binary, ND, poly, relationship anarchist, generally queer.
- No alt text (request) = no boost.
- Boosts OK for all boostable posts.
- DMs are open.
- Flirting welcome, but be explicit if you want something out of it!
- The devil doesn't need an advocate; no combative arguing in my mentions.
Sometimes horny on main (behind CW), very much into kink (bondage, freeuse, CNC, and other stuff), and believe it or not, very much a submissive bottom :p
My spoons are limited, so I may not always have the energy to respond to messages.
Strong views about abolishing oppression, hierarchy, agency, and self-governance - but I also trust people by default and give them room to grow, unless they give me reason not to. That all also applies to technology and how it's built.
Joined Aug 2019
Sven Slootweg
boosted

"The privacy invading feature that was patched into your browser and silently turned on by default was announced on our browser's blog 2 years ago so why are you so mad?"
My dude I'm probably in the top 0.01% of humans alive advocating for your product and I have never read your fucking blog because even I think "keeping up on the blog of the browser I use" is a fucking weirdo move
no context
The marker has experienced an unscheduled relocation event
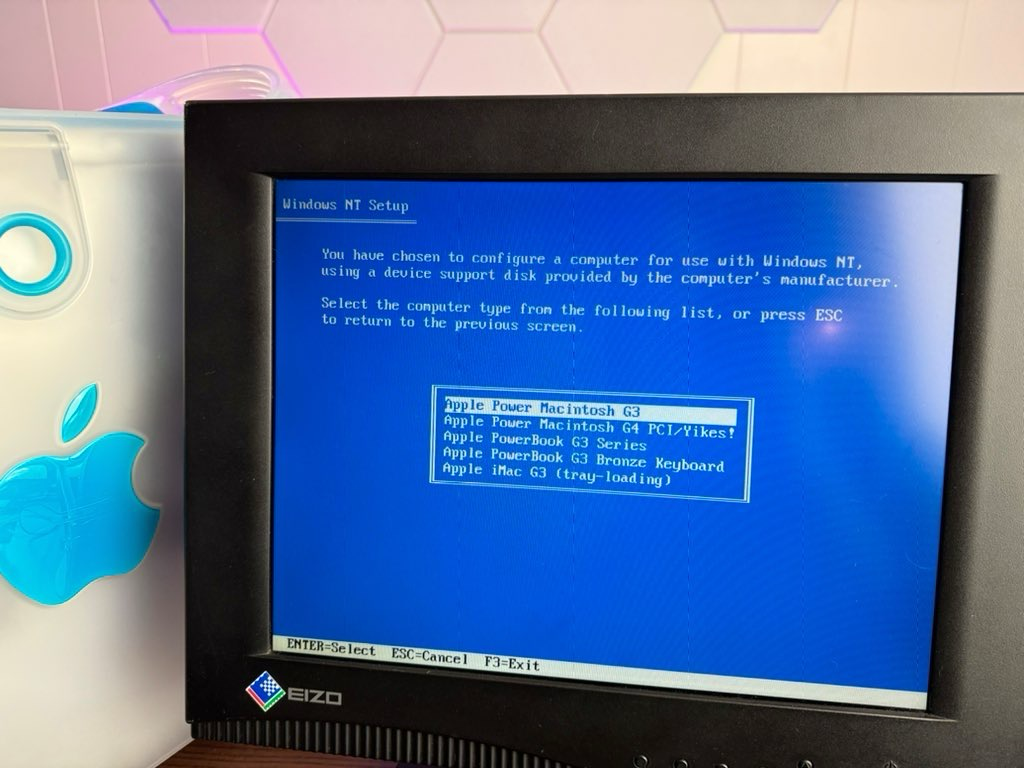
Testing my Wayland implementation by repeatedly turning a monitor on and off 🙃
wayland
The problem with Wayland is really not the protocol itself, nor that it is extension-based (that is actually a very good thing!), nor some weird conspiracy theory about it 'competing' with Xorg or being some kind of 'takeover' (it's the same people developing it! It's effectively just the next version.)
The real, actual problem with Wayland is that some desktop environments started defaulting to its use before it and its ecosystem were at feature parity with the systems and tools people were already using. Some projects jumped the shark. That's it.
We can be critical of something like Wayland without losing all nuance and inventing conspiracies and doom that don't actually exist.
Sven Slootweg
boosted

neverending cw meta
💠 yes, the violence is pervasive and constant. i am well aware. i am looking for a staging area to address it in a controlled manner. constant exposure is not that
Sven Slootweg
boosted

Pssst: influencers struggle with Mastodon because it's harder to influence people here. It's not because this place isn't neat.
Sven Slootweg
boosted

thoughts about legally shaky software licenses, somewhat hot take
@joepie91 "Your software will be legally risky to *any* kind of high-profile organization"
adding to that very specifically: this includes any distro other than AUR, nixpkgs, flathub, and snapcraft.
Sven Slootweg
boosted

Sven Slootweg
boosted

thoughts about legally shaky software licenses, somewhat hot take
So there's an increasingly common argument in favour of licenses that prohibit using the software for evil, or other difficult-to-define restrictions - the argument goes that it's *good* that it's unclear from a legal perspective, because that scares off the people you don't want using your software.
While that is true, and I agree with the *spirit* of the idea, I think that that's overlooking the collateral damage of this approach, which has two main forms:
1. Your software will be legally risky to *any* kind of high-profile organization, *including* the ones doing good work, and so it will be unavailable to them too
2. More insidiously, it makes it very difficult to build on top of, limiting the benefit it has to the *desirable* users. I'll explain this one more below.
Building on top of someone else's software is usually a big decision that's mostly irreversible, you become entirely dependent on the upstream; you need a pretty large amount of trust in the upstream to make that kind of decision, as the future of your project (and all the work you've put into it) will hinge on it.
This is a problem especially in the context of disabled and otherwise margnalized folks who are trying to tackle difficult problems; they'll often have a very limited amount of energy, and will want to make it count.
That means that they are both a) dependent on building on top of other people's work, to reduce the energy that's needed to build a thing, and b) *particularly* badly affected if something goes wrong with the upstream, and therefore need an even higher level of trust.
Not only that, but those same marginalized folks are also some of the most vulnerable to legal pressure, including from eg. copyright trolls.
All this creates a situation where such 'shaky' licenses become a hazard; anything licensed like that may not be safe to build upon, and even if it is, their *own* project may get disregarded by others because it inherits the shakiness of the upstream's license - and they may well be targeting a whole different demographic that *does* care about this, even if the upstream doesn't.
The end result is that shakily-licensed software is not safe to build on, and so you end up severely limiting how many 'levels' of "building on top of other people's work" are possible with it - and that may sound appealing from the perspective of a 'dependencies bad' ideology, but it hampers the ability for marginalized communities to construct alternative systems and infrastructure more broadly.
This is why I don't like those kinds of licenses. Doing this on a license level all but guarantees that it is a threat only to the least privileged people, while the likely intended targets (governments, corporations) can mostly just ignore such restrictions anyway and get away with it.
If you *must* use such licenses, then please at least make sure you have an alternative solution to the question of "how are people going to be able to collaborate around this and build non-oppressive systems".
But really, there are probably better ways to scare off governments and corporations than a legal system that's stacked in their favour.
Sven Slootweg
boosted

US pol: stop drinking that doom juice all of ya'll
Though I might dance & celebrate when Biden wins, it will not be for him. It'll be in spite of what he & every mealy-mouthed norms-anxious compromiser has done to put us here. And then, when I'm done dancing, (it may take a moment) I will turn around and put my focus in a new place.
I'm filled with optimism because all caution is gone from my body. We can't afford an ounce of that.
Sven Slootweg
boosted

Whenever I ponder the advancements of my field I get thoroughly dejected. Take the latest "great innovations":
- **Targeted ads** ended privacy in a way that makes Gestapo look like silly children
- **Crypto** gave rise to the scourge of ransomware
- **"Self-driving" cars** destroying our hopes for good public transportation
- **AI** turning the semantic web into a web of lies
If you're not an anarchist/communist by now, you're not really paying attention.
Sven Slootweg
boosted

I should start a penalty piggy bank for everytime I don't follow my own #gamedev advise 😅 this time, I did not play through the new build version after uploading
Sven Slootweg
boosted

The sentiment disconnect on 'AI' between tech and the public: https://www.baldurbjarnason.com/2024/sentiment-disconnect/
You know, perhaps the idea of a centralized search engine for the whole web - *any* centralized search engine - was just a major design mistake of the early web, and we should all have been working on community-curated search engines instead.
Sven Slootweg
boosted
POLL: What type of device are you using, RIGHT NOW, when you see this question?
(Please note I am not asking for opinions on the merits of devices, nor do I want to know the other devices you have. I want to know what device you're using to answer this question right now.)
Sven Slootweg
boosted

Hey y'all! Quick reminder that you can still sign up to attend #SolsticeSchool talks until the event itself, here ✨ https://solsticeschool.scholar.social/2024/programme
What talks are you most looking forward to attending?!
Sven Slootweg
boosted

oh i get it. it's called "cgit" because its "cgi git" but also "a git frontend in c" that lets you "see git"
Sven Slootweg
boosted

{kind=link}
[RSS] Linksys Velop Routers Caught Sending WiFi Creds in the Clear
https://hackaday.com/2024/07/15/linksys-velop-routers-caught-sending-wifi-creds-in-the-clear/
https://hackaday.com/2024/07/15/linksys-velop-routers-caught-sending-wifi-creds-in-the-clear/
Sven Slootweg
boosted
seekseek devlog, long-ish, technical details
I'm currently working on the auto-expiry of dependent tasks, ie. tasks which should be run once another task has completed. This is somewhat tricky.
For a bit of background: in srap (the working name for the backend), everything is expressed as 'items' with 'tags', and 'tasks' which are run on items that match the tags configured for those tasks. Tasks can then, at runtime, decide to invoke functions that create or modify items in the dataset (by name or otherwise), and assign tags.
It's possible for multiple tasks to run on items with the same tag, and it's also possible for those tasks to specify dependencies on each other; for example, given a page ID, you may want to 1) scrape the page contents and only then 2) normalize the scraped contents to some standard format, as separate tasks.
Now the challenge here is to ensure that once task 1 is re-run (because the TTL expires and it needs to be re-scraped), task 2 will *also* be re-queued. There's no explicit queue, the queue is just "whatever items are eligible tag-wise and do not have a recent-enough successful run registered for a task".
This is made difficult by the fact that the backend doesn't actually have a full dependency graph! It can know that task 2 dependsOn task 1, but the item may have been originally created by a task 0 which scraped a list of items (like a sitemap), and there's nothing telling the backend that task 0 can create page ID items, other than it just *happening to do so*.
The solution I've come up with so far, is to expire a taskRun for an item under two circumstances, checked whenever an item is modified:
1. The task in question does not have any dependencies, ie. it is the root/first task to run for a given tag - and the task that *modified* the item would itself never run for that item (to prevent cycles of dependents re-triggering the root task). This handles the "list -> item" case.
2. The task is a direct dependency of the task that is doing the modifying. This handles the "two tasks for one item with a dependency relation" case.
Now to actually implement this :)
- Website
- http://cryto.net/~joepie91/
- Matrix
- @joepie91:pixie.town
- Pronouns
- they/them, he/him, whatever, it's not like I have any idea either 🙃
Technical debt collector and general hype-hater. Early 30s, non-binary, ND, poly, relationship anarchist, generally queer.
- No alt text (request) = no boost.
- Boosts OK for all boostable posts.
- DMs are open.
- Flirting welcome, but be explicit if you want something out of it!
- The devil doesn't need an advocate; no combative arguing in my mentions.
Sometimes horny on main (behind CW), very much into kink (bondage, freeuse, CNC, and other stuff), and believe it or not, very much a submissive bottom :p
My spoons are limited, so I may not always have the energy to respond to messages.
Strong views about abolishing oppression, hierarchy, agency, and self-governance - but I also trust people by default and give them room to grow, unless they give me reason not to. That all also applies to technology and how it's built.
Joined Aug 2019
